Five questions (and answers) about preprints
(This post originally appeared on the Coast and Ocean Collective Blog)
After the last post, Giovanni asked me to respond to five questions.
1) What about reviewing, are you saying that reviewing of scientific manuscripts is not necessary?
My previous post purposely avoids discussion of peer-review. If you look at the graphic of the earlier post taken from the Wouters et al. 2019 article, one role of a journal is to certify that published work has been evaluated. I think readers need to understand that preprints are not evaluated. On EarthArXiv, all manuscripts that are not peer-reviewed must have notice stating as much.
But thinking about peer-review and evaluation brings up some deeper questions. By assuming that an article is true or valid just because it is typeset in a journal is ridiculous idea — the burden of convincing a reader is on the author based on their work. My point is that perhaps we should remember that most of use read and evaluate papers for ourselves — regardless of where it is published.
Additionally, most journals hide peer review reports (the Copernicus/EGU journals being an exception) — most of the time, we are just assuming that the peer reviewing process was performed adequately for published papers. This is not the case for published peer review reports (e.g., the Copernicus/EGU journals) a reader can actually read and understand the peer reviewing process for a given paper, but hidden review reports force a reader to trust that the journal publisher, the editors, and the reviewers all did an adequate job.
Lastly, there are initiatives to decouple review from journals. For example, PREreview is an initiative focused on reviews for preprints. I think it’s a neat idea if journal clubs focus on preprints, and produce review reports that could be relayed to the author. Another example is PubPeer.
2) Are preprints just a stop-gap solutions or are they a general solution to problems in scholarly publishing?
I think preprints are part of a larger solution to some problems in scholarly publishing. There are bigger issues though, many having to do with the costs to authors (page charges; OA fees) and the cost of journal subscriptions for libraries. A clear next step is to start to develop free open access journals, and potentially even journals that could potentially work on top of the preprint servers. here are some really inspiring examples:
Journals like VOLCANICA are breaking new ground for the Earth sciences by creating a free, open access journal with a v. low operating cost (500 euros per year) for the entire journal and transparency in the breakdown of those costs. Here is the editorial — https://doi.org/10.30909/vol.01.01.i-ix
Another journals with low operating costs and transparency on how costs are used is JOSS — Journal of Open Source Software — https://joss.theoj.org — operating costs of ~$3.50/per article. Joss runs on Github, and here is the editorial describing the model and costs: https://doi.org/10.7717/peerj-cs.147)
Lastly an example of a journal that explicitly leverages preprint infrastructure is Discrete Analysis — http://discreteanalysisjournal.com/for-authors. An author submits an article to a preprint server, in this case ArXiv, and tells the journal they would like to submit. The journal organizes reviews, and if it is accepted, the article is given a special LaTeX template to indicate it was reviewed, and the new version is resubmitted to ArXiv.
3) What about papers that get rejected? Especially if a paper is rejected from a short-form journal and needs to go to a long-form Journal?
Preprints have version control, so if the paper needs to change to respond to criticism, or the authors need to adjust formatting for a different journal, then the preprint is replaced with a new copy.
4) Can I cite preprints?
Yes, preprints can and should be cited. Preprints are given a DOI, and this can be used in the journal citation. EarthArXiv preprints are also indexed by Google Scholar. In the case that people have cited your preprint and you now have a published journal article, Dan Ibarra wrote a nice summary on twitter on how to merge these two entries in Google Scholar.
5) Are you sure about how good it is for early career researchers? Are there risks?
In my opinion, I think preprints are really great for early career researchers. I think there are two issues with preprints that might be perceived as risks for researchers — first, if a paper is rejected and needs to be reformatted for a new journal. Second, if there is an error in a paper and it needs to be corrected. If there are errors in a paper, the author can easily issue a correction in the form of a new version of the preprint. Error correction becomes easier and hopefully faster than dealing with a journal article. Reformatting is solved in the same way — a new version of the preprint can be produced. Perhaps having multiple versions of a preprint might make a researcher feel self conscious or embarrassed, but as a community we should destigmatize this process of versioning of preprints (and all scholarly artifacts, for that matter). Error identification and correction is an important part of scientific process, and journal choices are often not controlled by early career researchers. Regardless, it’s likely that only a rare few people will dig through old preprint versions to determine the changes that authors made.
My personal belief is that the rewards of visibility to written scientific work outweigh anything that can be called a risk.

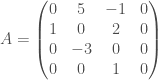
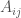 denotes the an edge from i to j with a given weight. In this model, it is the mood that scientist i has toward scientist j . (Some other texts do the reverse convention).
denotes the an edge from i to j with a given weight. In this model, it is the mood that scientist i has toward scientist j . (Some other texts do the reverse convention).
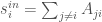
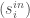 ).
). and
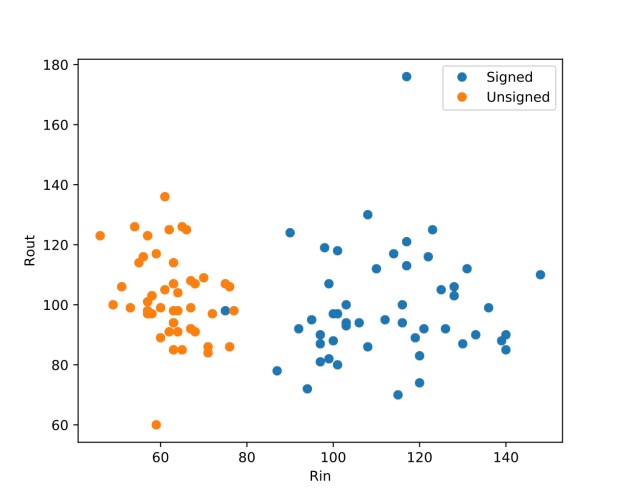
and  ) will be a sum of extreme positives and negatives — this is not very descriptive because it can lead to 0 strength. Instead I want to look at the range of incoming and outgoing weights, or:
) will be a sum of extreme positives and negatives — this is not very descriptive because it can lead to 0 strength. Instead I want to look at the range of incoming and outgoing weights, or: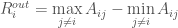 which denotes the maximum outgoing weight minus the minimum outgoing weight.
which denotes the maximum outgoing weight minus the minimum outgoing weight.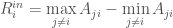 which denotes the maximum incoming weight minus the minimum incoming weight.
which denotes the maximum incoming weight minus the minimum incoming weight.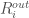 and
and 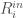 , for each scientist.
, for each scientist.