(This post originally appeared on the Coast and Ocean Collective Blog)
Preprints are non-peer-reviewed scholarly documents that precede publication in a peer-reviewed journal. Several disciplines like Physics, Astronomy and computer Science have been using preprints through arXiv for decades. Other disciplines are catching on, notably the biological sciences (See bioRxiv), and a variety of other discipline specific preprint services (e.g., here). There are many great articles and blog posts discussing preprints recently— common questions, critiques, misconceptions, concerns, etc. — here are three especially useful introductions:
1) Bourne PE, Polka JK, Vale RD, Kiley R (2017) Ten simple rules to consider regarding preprint submission. PLoS Comput Biol 13(5): e1005473. https://doi.org/10.1371/journal.pcbi.1005473
2) Sarabipour S, Debat HJ, Emmott E, Burgess SJ, Schwessinger B, Hensel Z (2019) On the value of preprints: An early career researcher perspective. PLoS Biol 17(2): e3000151. https://doi.org/10.1371/journal.pbio.3000151
3) A recent comprehensive look by Sheila Saia for the Young Hydrologic Society website is particularly useful for the Earth and Environmental scientists.
Full disclosure: I am a big advocate for preprints, interested in preprint adoption as a topic of study, and I am a current member of the EarthArXiv community — EarthArXiv is a community run preprint server for the Earth sciences (Narock et al. 2019). We have a very active community (especially on twitter!) so please bring us your questions/comments/concerns/clarifications.
To me, there are too many interesting facets about preprints to discuss in a single post. Here, I focus on some ways in which preprints compliment existing, more traditional ways of publishing — so we need to start by looking at scholarly communication and scholarly publishing, specifically journals.
A recent comment by Wouters et al (2019) outlined 5 roles for journals:

[Graphic from Wouters et al (2019) ]
I want to focus on discussing preprints in relation to task 1 (Registering) and 5 (Archiving). These are tasks that a scientific journal currently does by giving submission dates and assigning a persistent identifier to a journal article (i.e., the digital object identifier; DOI). In my opinion, these are tasks that we do not necessarily need a scientific journal to do. Instead, a preprint can accomplish these tasks — establishing precedent for an idea, and providing a means of citing the idea via a DOI.
If we rely on journals to do these tasks, the process can be attenuated. Peer-review can take months (or even years) before an article is published and visible to a community of peers. This is not a complaint against peer-review or the peer-review process — I am arguing here that several steps can occur before peer-review. My opinion is that bundling the registration of an idea (Task 1) and the archiving of idea (Task 5) with the peer-review process is suboptimal for one key reason:
No one can read, cite, or respond to an idea when the paper is hidden in review — only the editor, AE, reviewers, and coauthors can read, engage with, explore, and think about the work. These ideas may be presented at conferences, but in the written record, they do not exist (e.g., many journals have policies discouraging citations to conference abstracts). Ideas that are preprinted have persistent identifiers (DOIs) and can (and should!) be cited and discussed by others — preprints exist.
As an early career scientist, this is especially important. Scholarly work in review with no preprint remains invisible to the broader community. Early career scientists often mention ‘in prep’ or in review articles on CVs — I’d argue that this is far less meaningful than linking to a preprint version (where people could actually read and cite you work). Again, preprints exist.
Being unable to read and cite articles that are in review in a transparent way hampers our ability to do science. Hiding articles through the review process is a form of information asymmetry — and a bizarre, imperfect hiding. I know about lots of work that remains hidden — I read about it as a grant or paper reviewer, I hear about it in passing from colleagues, and conference presentations give a glimpse of what will be published in the next few years — but I cannot cite these ideas or these works unless there are preprints. Put another way — there is a subset of ideas that I know about, but can’t share with colleagues. This is strange.
This is where preprints come into the picture. Preprint services like EarthArXiv can 1) store papers (i.e., registering intellectual claims associated with author names and submission timestamps), and 2) assign DOIs and archive scholarly artifacts. Therefore preprint services accomplish Task 1 (registering) and Task 5 (archiving) in the Wouters et al (2019) taxonomy. Preprints leave the other tasks (curating, evaluating, and disseminating) for other services such as scientific journals.
My argument here is that we should unbundle the services that journals provide to increase the flow of information. Preprints can accomplish some of these tasks faster, cheaper, and better than traditional journals.
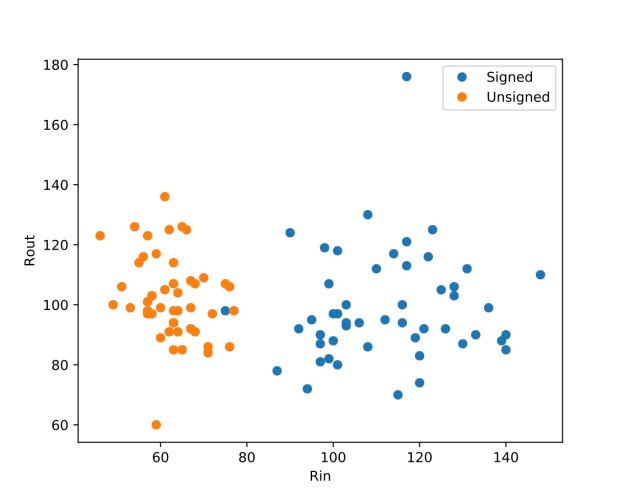
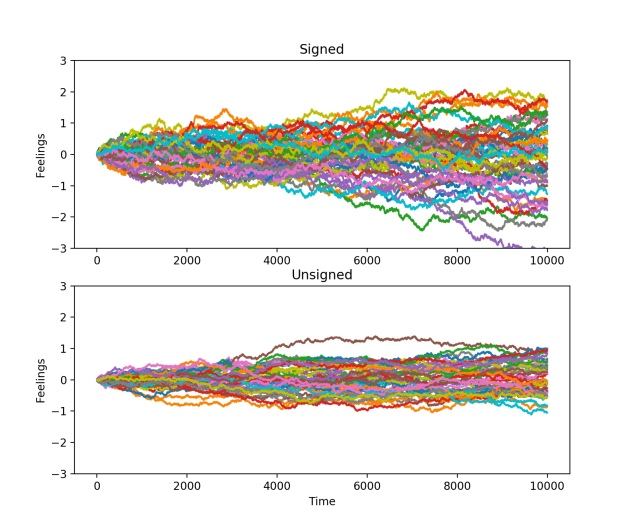
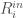 is the maximum incoming weight minus the minimum incoming weight. This represents the range of feelings all other scientists have about scientist i.
is the maximum incoming weight minus the minimum incoming weight. This represents the range of feelings all other scientists have about scientist i.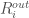 is the maximum outgoing weight minus the minimum outgoing weight. This represents the range of feelings scientist i has about all other scientists in the discpline.
is the maximum outgoing weight minus the minimum outgoing weight. This represents the range of feelings scientist i has about all other scientists in the discpline.
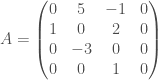
 denotes the an edge from i to j with a given weight. In this model, it is the mood that scientist i has toward scientist j . (Some other texts do the reverse convention).
denotes the an edge from i to j with a given weight. In this model, it is the mood that scientist i has toward scientist j . (Some other texts do the reverse convention).
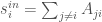
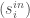 ).
). and
and  ) will be a sum of extreme positives and negatives — this is not very descriptive because it can lead to 0 strength. Instead I want to look at the range of incoming and outgoing weights, or:
) will be a sum of extreme positives and negatives — this is not very descriptive because it can lead to 0 strength. Instead I want to look at the range of incoming and outgoing weights, or: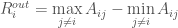 which denotes the maximum outgoing weight minus the minimum outgoing weight.
which denotes the maximum outgoing weight minus the minimum outgoing weight.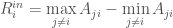 which denotes the maximum incoming weight minus the minimum incoming weight.
which denotes the maximum incoming weight minus the minimum incoming weight.